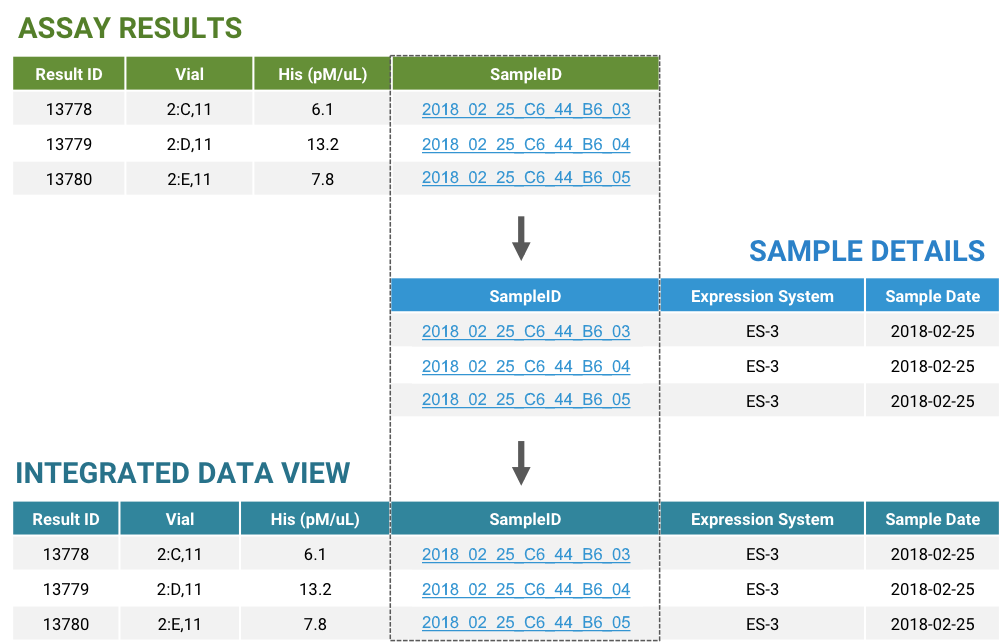
There is no single test that is run to assess the safety, stability, and scalability of a biologic treatment. Instead, these key characteristics are measured using a variety of analytical and observational tests. In order to assess the biologic’s viability as a therapeutic, scientists must be able to analyze all of these data points in conjunction with one another. When R&D teams are utilizing spreadsheet based systems for data management, this aggregate analysis requires manual integration of data from multiple datasets stored in a variety of formats.
Manually integrating datasets can pose a number of productivity challenges for R&D teams.
- Manual integration is often a time-consuming process that can take valuable time away from your scientists.
- It is difficult to ensure that data is integrated in a consistent manner across projects and team members.
- Manual manipulation of data means a higher chance of human error.
LabKey Biologics automates the integration of datasets, and prepares data for analysis in an efficient and reliable manner. Automating the integration of data with LabKey Biologics can enhance R&D productivity in the following ways.
Saving Your Scientists Time
LabKey Biologics stores R&D data including molecular entity definitions, sample details, and analytical results in a consistently structured manner, preparing it for seamless integration with related data of other types. The system then automatically builds relationships between related data, so that scientists can easily explore data through the UI or export integrated data for analysis using external tools. Automatically building connection between structured data types saves scientists hours of time that would be spent on manually integrating data, and allows them to dedicate more time to analysis.
Ensuring Consistent Data Processing
Relationships between data types stored in LabKey Biologics are defined on a global level, ensuring that data connections are built consistently across all projects. Users can also design custom grid views of data to surface data points of interest in a single grid. These custom views can be saved and applied across groups of samples or experiments, ensuring that data is presented consistent across a research project.
Minimizing Human Error
Perhaps the most straight-forward benefit of utilizing LabKey Biologics for research data integration is minimizing the potential for human error. Manual integration can lead to copy/paste mistakes, problemattic auto-formatting, and other errors that can be hard to detect and significantly hinder analysis. Using LabKey Biologics to integrate datasets eliminates the risk of these types of errors during the integration process, and provides additional mechanisms to protect against human error during data analysis including audit logging of data access and transformations.
With LabKey Biologics, biopharma R&D teams can automate data integration, accelerating the integration process and ensuring the generation of high quality datasets. Request a demo of LabKey Biologics or explore the LabKey Biologics trial environment, free for 30-days.

 There are several ways in which the visibility into previously generated data provided by LabKey Biologics can prevent duplicate work in the lab. Perhaps a bench scientist is interested in understanding what protein expression occurs under a particular set of conditions. Unbeknownst to them, an experiment testing that same protein expression was completed 6 months earlier by another team member. Using LabKey Biologics, this researcher could search historical experiments with those same conditions and view their results, saving them the time and resources of conducting a new experiment.
There are several ways in which the visibility into previously generated data provided by LabKey Biologics can prevent duplicate work in the lab. Perhaps a bench scientist is interested in understanding what protein expression occurs under a particular set of conditions. Unbeknownst to them, an experiment testing that same protein expression was completed 6 months earlier by another team member. Using LabKey Biologics, this researcher could search historical experiments with those same conditions and view their results, saving them the time and resources of conducting a new experiment. A lack of visibility into your team’s previously generated data can also lead to duplicate records in your bioregistry. LabKey Biologics provides easy mechanism for searching/sorting existing data to locate previously registered entities, and also conducts an automated uniqueness check on each entity registered in the system. These tools ensure that related data is connected to the correct entity from the start, and removes the need for downstream data clean-up.
A lack of visibility into your team’s previously generated data can also lead to duplicate records in your bioregistry. LabKey Biologics provides easy mechanism for searching/sorting existing data to locate previously registered entities, and also conducts an automated uniqueness check on each entity registered in the system. These tools ensure that related data is connected to the correct entity from the start, and removes the need for downstream data clean-up.
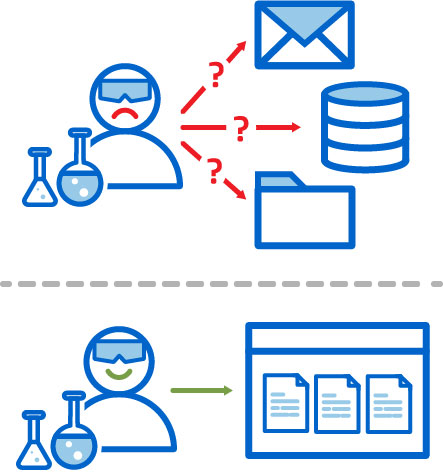
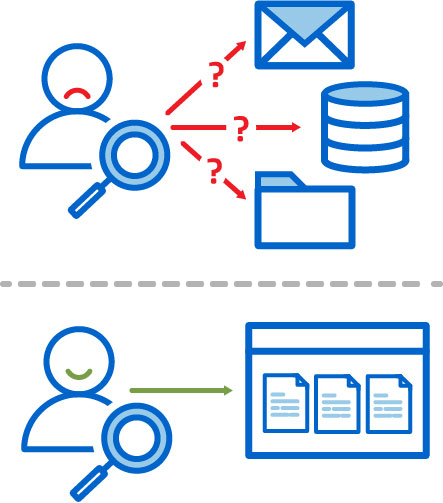 Team Members Know Where to Find Data
Team Members Know Where to Find Data

 Task Management for Bench Scientists
Task Management for Bench Scientists Experiment View of Assay Data
Experiment View of Assay Data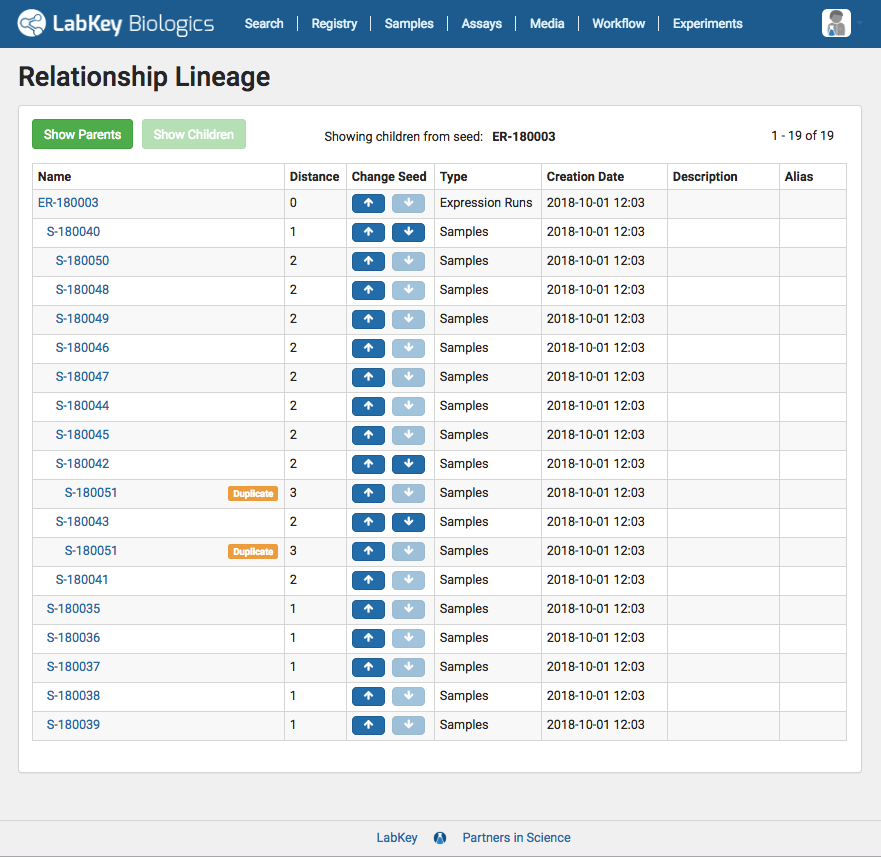


 Consistent Batch Preparation
Consistent Batch Preparation Following the Media Trail
Following the Media Trail
 The focus of pharmaceutical and biotech research has seen a significant shift in recent years. Many research teams are no longer driving towards building small molecules, but are instead focused on designing new protein-based therapeutics. Protein engineers at these organizations are often responsible for the structural design of target molecules as well as the experimental protein production and characterization of their designs.
The focus of pharmaceutical and biotech research has seen a significant shift in recent years. Many research teams are no longer driving towards building small molecules, but are instead focused on designing new protein-based therapeutics. Protein engineers at these organizations are often responsible for the structural design of target molecules as well as the experimental protein production and characterization of their designs.