For many laboratories, growth and the changes that come along with it can be both exciting and challenging to sample management operations.
Without careful planning and forethought about sample management, even the most organized lab down can go down a spiral of compounding challenges. Misplaced samples, lapses in data integrity, and confusion on workflow steps are just a few of the difficulties that may arise when a laboratory is experiencing growth. A lab undergoing “growth” may be:
- Processing a higher volume of samples overall or a higher volume of a specific type of sample
- Implementing new sample processing procedures, experiments, and data collection methods
- Expanding their existing operations and the laboratory staff needed to support changes
In this webinar, we present five real-world strategies to help your lab get ahead of the challenges you may face. These include:
-
Change is difficult- be flexible!
A growing lab will experience many forms of change. Be flexible and ready to adapt at every stage. -
Plan for your metadata and sample tracking needs.
Keep the sample information needed for accurate tracking at the forefront of your planning. As your lab grows, the data you need to capture may change. -
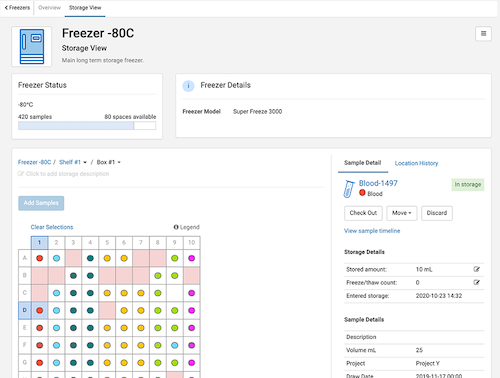
Don’t let your freezers get out of control.
As your sample storage needs change, be sure to prioritize freezer organization from the start. -
Standardize your lab processes.
By taking even small steps toward standardizing processes, labs can optimize their efficiency and ensure a smooth evolution. -
Research sample management systems.
Choosing the right (or wrong) sample management system can have a lasting impact on your lab.
With preparation, your lab can successfully navigate change while improving the productivity and efficiency of your sample management operations. Watch the webinar below:
LabKey Sample Manager is an easy-to-use sample management software designed to help labs efficiently track samples, define laboratory workflows, and unify samples with assay data.
Sample Tracking – End-to-end sample tracking features including chain-of-custody tracking, sample types and sources, and lineage views
Freezer Management – Flexible and intuitive management of freezer capacity and sample storage locations.
Sample Data Integration – Integrate assay data with your samples and assign metadata for a complete picture of your ongoing experiments
Sample Management Workflow – Assign samples to user-defined workflows and monitor the workflow completion status at each stage for every sample
Explore Sample Manager – register to take a product tour!